Which data should be preserved and shared?
At SDU Library we only encourage that you produce and share FAIR research data. We fully understand that not all data can be published as fully open. Given that, we recommend that the following data be shared and/or preserved:- The data needed to validate results in scientific publications (minimally!).
- The associated metadata: the dataset’s creator, title, year of publication, repository, identifier etc.
- Even when you can not share your data due to GDPR or confidentiality, you can always share your metadata.
- Follow a metadata standard in your line of work, or a generic standard, e.g. Dublin Core or DataCite, and be FAIR.
- The repository will assign a persistent ID to the dataset (often a DOI): important for discovering and citing the data.
- Documentation: code books, lab journals, informed consent forms – domain-dependent, and important for understanding the data and combining them with other data sources.
- Software, hardware, tools, syntax queries, machine configurations – domain-dependent, and important for using the data.
- Alternative: information about the software etc.
Basically, everything that is needed to replicate a study should be available. Plus everything that is potentially useful for others.
How can you prepare sensitive data for sharing?
Although it may not be possible in all cases, it is a good idea to obtain informed consent from the participants in your study to allow for publication of their anonymized data from the research. For more advice on how to deal with sensitive data, please see:
- the guides here on Data protection at SDU
- our page on GDPR and legal issues
Modifying sensitive data for public release
Sensitive data that contain potentially identifying information- whether it be human subject data or other types of sensitive data - will likely need to be modified prior to sharing these data with the public. It is important that these modifications are made in order to protect participant confidentiality, the location of endangered wildlife, or for other relevant reasons. However, these modifications may affect the data to the point where reproducibility or additional subsequent research by others is no longer possible. You might consider retaining multiple versions of the data: one that is suitable for public release, and one that is suitable for further research but that is available on a highly restricted basis.
Types of identifying information
Identifying information is classified as one of two types: direct and indirect.
Direct identifiers
These data point directly to an individual and are typically removed from data sets before sharing with the public.
These may include:
- name
- initials
- mailing address
- phone number
- email address
- unique identifying numbers, like Social Security numbers or driver's license numbers
- vehicle identifiers
- medical device identifiers
- web or IP addresses
- biometric data
- photographs of the person
- audio recordings
- names of relatives
- dates specific to individual, like date of birth, marriage, etc.
Indirect identifiers
These may seem harmless on their own, but can point to an individual when combined with other data. It has been recommended (see BMJ article reference below) that datasets containing three or more indirect identifiers should be reviewed by an independent researcher or ethics committee to evaluate identification risk. Any indirect information not needed for the analysis should be removed. It may be reasonable to supply some of these types of data in aggregated form (like ranges of annual incomes instead of exact numbers).
Indirect identifiers may include:
- place of medical treatment or doctor's name
- gender
- rare disease or treatment
- sensitive data like illicit drug use or other "risky behaviors"
- place of birth
- socioeconomic data, like workplace, occupation, annual income, education, etc.
- general geographic indicators, like postal code of residence
- household and family composition
- ethnicity
- birth year or age
- verbatim responses or transcripts
Why share data?
It's part of good data practice.

Cut down on academic fraud
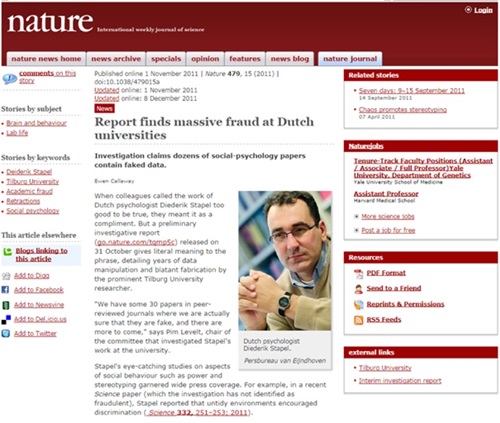
Validate results
"It was a mistake in a spreadsheet that could have been easily overlooked: a few rows left out of an equation to average the values in a column. The spreadsheet was used to draw the conclusion of an influential 2010 economics paper: that public debt of more than 90% of GDP slows down growth. This conclusion was later cited by the International Monetary Fund and the UK Treasury to justify programmes of austerity that have arguably led to riots, poverty and lost jobs."

More scientific breakthroughs
Data sharing enables scientific breakthroughs in the human brain studies as well as Alzheimer’s Disease, Type 2 Diabetes, Rheumatoid Arthritis and Lupus and many others.
A citation advantage
A study that analysed the citation counts of 10,555 papers on gene expression studies that created microarray data, showed: “studies that made data available in a public repository received 9% more citations than similar studies for which the data was not made available".
Further reading
Hrynaszkiewicz, I, Norton, ML, Vickers, AJ and Altman, DG. "Preparing raw clinical data for publication: guidance for journal editors, authors, and peer reviewers." BMJ 2010;340:c181.
"Preparing Data for Sharing" from the Inter-University Consortium for Political and Social Research (ICPSR). (2012).
Guide to Social Science Data Preparation and Archiving: Best Practice Throughout the Data Life Cycle (5th ed.). Ann Arbor, MI.
This page is adapted from the Stanford University Library Data Management Services website and the RDM OpenAIRE handbook.
Frequently asked questions
The general steps for finding a non-institutional data repository are:
- Use a disciplinary repository if there is one;
- Alternatively, use the institutional repository, if you have one where the data will also be available for the long term;
- Use the catch-all repository Zenodo, maintained by CERN;
- Search the global re3data.org portal for a fitting repository - this provides several filtering options.
- OR look at a more detailed guide for field specific data repositories here.
It’s not easy to evaluate the quality of repositories, because this is influenced by many external factors, starting with the mission of the repository. For instance, does it explicitly aim for long-term preservation - with the appropriate expertise and budget - or not? Is it dedicated to a specific research community and familiar with their data formats, or is it generic? However, if you focus on repositories that are certified as being trustworthy, you simplify your selection process. So, if you don’t have a disciplinary repository, and use the re3data.org portal for your search, we recommend that you filter on “Certificate” and look for the red icon (unfortunately, OpenDOAR has no such filter).
This text is adapted from the OpenAIRE guide on trustworthy repositories.
Open data is data that can be freely used, re-used and redistributed by anyone - subject only, at most, to the requirement to attribute and sharealike.
The full Open Definition gives precise details as to what this means. To summarize the most important:
- Availability and Access: the data must be available as a whole and at no more than a reasonable reproduction cost, preferably by downloading over the internet. The data must also be available in a convenient and modifiable form.
- Re-use and Redistribution: the data must be provided under terms that permit re-use and redistribution including the intermixing with other datasets.
- Universal Participation: everyone must be able to use, re-use and redistribute - there should be no discrimination against fields of endeavour or against persons or groups. For example, ‘non-commercial’ restrictions that would prevent ‘commercial’ use, or restrictions of use for certain purposes (e.g. only in education), are not allowed.
This text is adapted from the Open Data Handbook.
The "Sorbonne Declaration" on research data rights affirms the commitment of the signatory universities to opening up research data and demanding a clear legal framework to regulate this sharing and to provide the means to put it in place.
The Declaration was published on January 28 2020 at the LERU website, and it is an important document to promote Open Data.
FAIR research data is data that has been prepared in accordance with the FAIR Guiding Principles published in 2016. These principles contain data management best practices that aim at making data FAIR: Findable, Accessible, Interoperable, and Reusable.
To learn more, visit the FAQ section of our page on data best practices here.