Prædiktioner på studieadfærd
“Data can only be understood backwards; but it must be lived forwards” sådan ville vi nok citere Søren Kierkegaard, hvis han havde levet i vores tid med big data, AI m.v.
Vi udvikler prognosemodeller til at forudsige studenteradfærd. Formålet er, at universitetet i tide, før tingene udvikler sig, kan træffe dataunderstøttede beslutninger til fremme af styrkepositioner og med henblik på at minimere risici i forhold til kritiske succesfaktorer, der beskriver studerendes adfærd.
Siden det succesfulde pilotprojekt fra foråret 2018 om forudsigelse af studenterfrafald for bachelorstuderende har dette delprojekt af projekt Advanced Analytics 2018-2021 været igennem EU-udbud i efteråret 2018, for at kunne købe kvalificeret assistance til udvikling af en egentlig driftsmodel. Hele 2019 er gået med udvikling den såkaldte Black Box model, der er præcis i forudsigelsen af individuelt frafald. I første omgang individuelle sandsynligheder for studerendes førsteårsfrafald.
SDU Analytics har i efteråret 2019 fået de første data ud af maskinlæringsmodellen, og arbejder på en kvalitetssikring af modellen, der forbereder den løbende vedligeholdelse og udvikling fremadrettet. Herefter er det tanken, at modellen fin-tunes, men også at den anvendes til at prioritere for hvilke uddannelser, der skal bygges white-box-modeller. White-box-modeller er maskinlæringsmodeller, der fortæller hvilke parametre, der bliver udslagsgivende. Dermed vil universitetet få mulighed for at justere på eksempelvis undervisning og servicetilbud til de studerende.
I løbet af foråret 2020 lanceres en applikation, der viser:
Når man ser på black box modellens prædiktionsevner for årgang 2018 på uddannelsesniveau med frafaldstruede studerende i forhold til det faktiske frafald på uddannelserne kan vi se, at modellen performer tilfredsstillende for de fleste uddannelser. Figurerne nedenfor er et sneak peak på de indledende findings.
Figur 1 er den klassiske vurdering af, hvor godt en statistisk model performer. Jo større andel i True Positive (at det forudsete realiseres) og i True Negative (at det ikke forudsete ikke realiseres), jo bedre er modellen.
”False Positive” er den lidt for rummelige model, der forudsiger frafaldsrisiko for studerende, der i sidste ende ikke falder fra. Hvis man vil minimere disse type 1 fejl skal man skrue på modellens parametre – det er er i høj grad spørgsmål om matematikken i modellen.
”False Negative”, såkaldt type II fejl, er værre, for det er typisk udtryk for at modellen er designet forkert eller at modellen mangler data. Det er både svært og dyrt at håndtere.
Ser vi på førsteårsfrafaldet for bahelorårgang 2018 ser vi i matricen i figur 2 nedenfor:
Samlet set fik modellens forudsigelser ret i 78% af tilfældene. Det er et godt udgangspunkt for at arbejde videre med modellen.
Der er 18%, hvor modellen forudsiger frafald uden at det er sket, modellen overdriver her risikoen for at falde fra indenfor det første studieår. Derfor må vi justere i modellen.
Det er kun 4% af det faktiske frafald, at modellen ikke spottede de studerende. Vi tester om vi kan minimere denne type fejl ved at inkludere flere data.

Der er uddannelser, hvor modellen performer bedre end for andre uddannelser – det vender vi tilbage til, når applikationen går i luften.
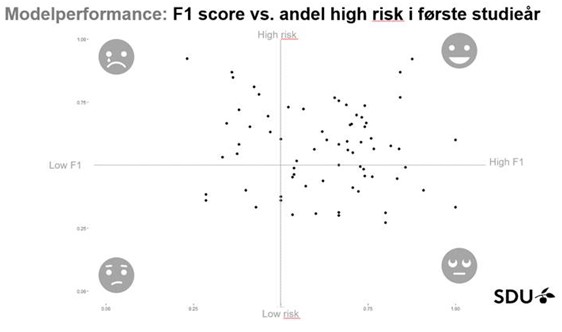
Figuren nedenfor viser fordelingen af SDU’s bacheloruddannelser i forhold til andel high-risk-studerende på uddannelsen versus modellens evne til at forudsige korrekt.Foreløbig kan det konkluderes, som det ses nedenfor, at for de fleste af SDU’s uddannelser giver black boks modellen en stærk prognose på førsteårsfrafaldet.
For nørderne.
Vi er på nuværende tidspunkt på ingen måde eksperter på dette område! Vi er på en rejse, hvor vi langsomt lærer mere og mere om modellen.
Nedenstående er medtaget for at give indtrykket af, at vi med denne black box model har forladt klassisk social science og en økonoms håndtering af 5 til 7 variabler i en multivariat analyse.
Nu er det data science, og ingeniørtilgangen med et andet programmeringssprog og en anden mere kompleks håndtering af data.
Teknisk er der tale om en RNN model (recurrent neural network som tilhører gruppen af artificial neural network modeller, der tillader skiftende dynamisk adfærd). Der er tale om den variation af RNN, der kaldes en LSTM model (Long Short-Term Memory Units), der er velegnet til tidsseriedata, og som kan rumme mange samtidige forhold i bevægelse.
Figuren nedenfor illustrerer kompleksiteten for RNN LSTM.
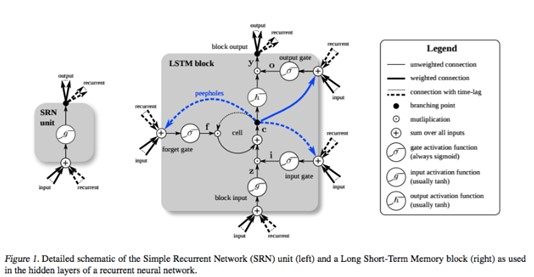
Kilde: https://skymind.ai/wiki/lstm
Prædiktioner på studenteradfærd er et af flere delprojekter i Projekt Advanced Analytics. Der eksperimenteres i projektperioden med at lave prædiktioner på studenteradfærd på syv kritiske succesfaktorer for uddannelseskvalitet.